2010 update:
Lo, the Web Performance Advent Calendar hath moved
Dec 8 This article is part of the 2009 performance advent calendar experiment. This is also the first ever guest post to this blog.
Please welcome the world-famous Christian Heilmann! And stay tuned for the next articles.
 Chris Heilmann is a self confessed data junkie and worked for over 12 years as a professional web developer. Having published several books on JavaScript, Accessibility and web development using web services he right now works as a developer evangelist for the Yahoo Developer Network. He blogs at http://wait-till-i.com/, has all his talks and videos at http://icant.co.uk/ and can be found on Twitter as @codepo8.
Chris Heilmann is a self confessed data junkie and worked for over 12 years as a professional web developer. Having published several books on JavaScript, Accessibility and web development using web services he right now works as a developer evangelist for the Yahoo Developer Network. He blogs at http://wait-till-i.com/, has all his talks and videos at http://icant.co.uk/ and can be found on Twitter as @codepo8.RSS is a wonderful format to get information from all kind of different sources. It is dead easy to provide, has a predictable (albeit limited) format and is very easy to use. The problem of course is that with the amount of different feeds used in one page its performance goes down.
The reason is the classic HTTP request issue - the more you negotiate, find and pull the slower your page renders. Therefore you need to try to shorten the time the calls happen.
Say you want to pull the following five RSS feeds and display them:
- http://code.flickr.com/blog/feed/rss/
- http://feeds.delicious.com/v2/rss/codepo8?count=15
- http://www.stevesouders.com/blog/feed/rss
- http://www.yqlblog.net/blog/feed/
- http://www.quirksmode.org/blog/index.xml
The least effective way of doing that is pulling and displaying them one after the other:
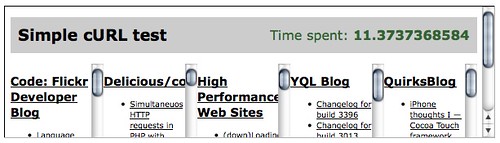
$oldtime = microtime(true); $url = 'http://code.flickr.com/blog/feed/rss/'; $content[] = get($url); $url = 'http://feeds.delicious.com/v2/rss/codepo8?count=15'; $content[] = get($url); $url = 'http://www.stevesouders.com/blog/feed/rss'; $content[] = get($url); $url = 'http://www.yqlblog.net/blog/feed/'; $content[] = get($url); $url = 'http://www.quirksmode.org/blog/index.xml'; $content[] = get($url); display($content); echo '<p>Time spent: <strong>' . (microtime(true)-$oldtime) .'</strong></p>'; function get($url){ $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($ch); curl_close($ch); return $output; } function display($data){ foreach($data as $d){ $obj = simplexml_load_string($d); echo '<div><h2><a href="'.$obj->channel->link.'">'. $obj->channel->title.'</a></h2>'; echo '<ul>'; foreach($obj->channel->item as $i){ echo '<li><a href="'.$i->link.'">'.$i->title.'</a></li>'; } echo '</ul></div>'; } }
Using Stoyan's Multi Curl function you already realise quite an increase in speed.
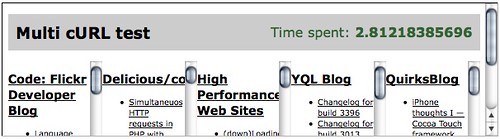
$data = array( 'http://code.flickr.com/blog/feed/rss/', 'http://feeds.delicious.com/v2/rss/codepo8?count=15', 'http://www.stevesouders.com/blog/feed/rss', 'http://www.yqlblog.net/blog/feed/', 'http://www.quirksmode.org/blog/index.xml' ); $r = multiRequest($data); display($r); function multiRequest($data, $options = array()) { // array of curl handles $curly = array(); // data to be returned $result = array(); // multi handle $mh = curl_multi_init(); // loop through $data and create curl handles // then add them to the multi-handle foreach ($data as $id => $d) { $curly[$id] = curl_init(); $url = (is_array($d) && !empty($d['url'])) ? $d['url'] : $d; curl_setopt($curly[$id], CURLOPT_URL, $url); curl_setopt($curly[$id], CURLOPT_HEADER, 0); curl_setopt($curly[$id], CURLOPT_RETURNTRANSFER, 1); // post? if (is_array($d)) { if (!empty($d['post'])) { curl_setopt($curly[$id], CURLOPT_POST, 1); curl_setopt($curly[$id], CURLOPT_POSTFIELDS, $d['post']); } } // extra options? if (!empty($options)) { curl_setopt_array($curly[$id], $options); } curl_multi_add_handle($mh, $curly[$id]); } // execute the handles $running = null; do { curl_multi_exec($mh, $running); } while($running > 0); // get content and remove handles foreach($curly as $id => $c) { $result[$id] = curl_multi_getcontent($c); curl_multi_remove_handle($mh, $c); } // all done curl_multi_close($mh); return $result; } function display($data){ foreach($data as $d){ $obj = simplexml_load_string($d); echo '<div><h2><a href="'.$obj->channel->link.'">'. $obj->channel->title.'</a></h2>'; echo '<ul>'; foreach($obj->channel->item as $i){ echo '<li><a href="'.$i->link.'">'.$i->title.'</a></li>'; } echo '</ul></div>'; } }
However, there are still two things that are annoying:
- You pull far more data than you really need
- You do all the request from your server
Yahoo Pipes has been used for that kind of task for quite a while, but the issue was that it is a visual interface and therefore hard to maintain. The server was also not the best performing out there.
The good news is that there is a new(er) kid on the block in Yahoo Land called YQL running on a massively fast server farm and with one purpose: making it easier to use web services, mix them and get only the data back that you want.
YQL in itself is a web service and you post queries to it that access other web services in a SQL style syntax. Normally you'd get RSS feeds using the RSS table, like so:
select * from rss where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the single RSS in the YQL console (you need a Yahoo account to log in). You can also see the single RSS retrieval output.
The issue with this is that it only retrieves the items of the RSS feed and not the title, which we need for the headings. Therefore we need to use the XML table:
select * from xml where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the single XML in the YQL console (you need a Yahoo account to log in). You can also see the single XML retrieval output.
This gives us the same data the normal cURL calls give us. The cool thing about YQL is though that you can filter the data you get back to the bare minimum. In our case, this means replacing the * with the title and the link of the feed and of the items:
select channel.title,channel.link,channel.item.title,channel.item.link from xml where url="http://feeds.delicious.com/v2/rss/codepo8?count=15"
See the filtered RSS in the YQL console (you need a Yahoo account to log in). You can also see the filtered RSS retrieval output.
In order to use this with all of our RSS feeds, we can use the in() command:
select channel.title,channel.link,channel.item.title,channel.item.link from xml where url in( 'http://code.flickr.com/blog/feed/rss/', 'http://feeds.delicious.com/v2/rss/codepo8?count=15', 'http://www.stevesouders.com/blog/feed/rss', 'http://www.yqlblog.net/blog/feed/', 'http://www.quirksmode.org/blog/index.xml' )
Check the aggregation in the console or the aggregation output.
This leaves all the hard work to the Yahoo Server farm. YQL pulls all the RSS feeds, adds one after the other and then gives it back to us as XML. We could simply use the generated URL from the console, but it is much more versatile to assemble the query in PHP:
$data = array( 'http://code.flickr.com/blog/feed/rss/', 'http://feeds.delicious.com/v2/rss/codepo8?count=15', 'http://www.stevesouders.com/blog/feed/rss', 'http://www.yqlblog.net/blog/feed/', 'http://www.quirksmode.org/blog/index.xml' ); $url ='http://query.yahooapis.com/v1/public/yql?q='; $query = "select channel.title,channel.link,channel.item.title,channel.item.link from xml where url in('".implode("','",$data)."')"; $url.=urlencode($query).'&format=xml'; $content = get($url); display($content); function get($url){ $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($ch); curl_close($ch); return $output; } function display($data){ $data = simplexml_load_string($data); $sets = $data->results->rss; $all = sizeof($sets); for($i=0;$i<$all;$i++){ $r = $sets[$i]; $title = $r->channel->title.''; if($title != $oldtitle){ echo '<div><h2><a href="'.($r->channel->link.'').'">'. ($r->channel->title.'').'</a></h2><ul>'; } echo '<li><a href="'.($r->channel->item->link.'').'">'. ($r->channel->item->title.'').'</a></li>'; if($title != $sets[$i+1]->channel->title.''){ echo '</ul></div>'; } $oldtitle = $r->channel->title.''; }; }
As you can see the loop to display the different RSS feeds a bit clunky and we could use an open YQL table to move the whole conversion to a server-side JavaScript. However, as it is the performance of this way of retrieving the RSS feeds beats all the others hands-down already:
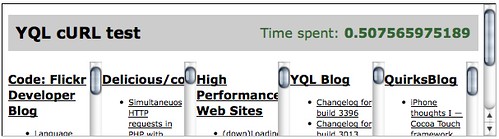
You can try it yourself, get the demo code from GitHub and run it on your own server to see the magic of YQL.




